Как отключить уведомления на Android?
Устанавливая каждое приложение, владелец смартфона соглашается с запросами на доступ к определенным данным и возможностям...
Шаг 2. Продолжаем расширять семантику, используя инструмент “Похожие фразы ”, который . Внедряя ключевики из этого отчета, вы максимально . А параметр “Сила связи” подскажет вам, используют ли эту фразу в своем семантическом ядре ваши конкуренты из топ-20. Чем выше число, тем больше сайтов используют исследуемую фразу и предложенный синоним.
Выраженный результат показывается на товарах, которые люди могут искать по-всякому. Например, подушки для спины.
Шаг 3. Последний шаг в расширении семантики - это сбор поисковых подсказок поисковой системы. Преимущество в том, что сервисы собирают информацию в режиме реального времени и вытаскивают сразу все поисковые подсказки, которые может предложить Яндекс/Google. Поисковики же предлагают только до 12 подсказок на фразу .


Чтобы выгрузить все подсказки, переходим в инструмент “Поисковые подсказки ” и выгружаем список.
Обратите внимание на облако популярных фраз, именно такие слова чаще всего ищут люди со словосочетанием “ортопедические матрасы”. Если среди фраз есть определенные размеры, бренды или тип изделия, то стоит включить их в ассортимент интернет-магазина.
Также под информационный тип ключевиков, как “лучшие матрасы для проблем с позвоночником”, вы можете подготовить статью к вам в блог, что станет дополнительным источником трафика и продаж .
Шаг 4. Сводим все отчеты в единую таблицу и чистим дубли с помощью плагина Remove Duplicate .


Потраченное время - до 5 минут. Зависит от количества ключевых запросов.
Пользуюсь сервисами вы уже выигрываете время перед теми, кто собирает, чистит и кластеризует семантику вручную . Чтобы понять разницу, попробуйте провести все описанные шаги, вытаскивая ключевые фразы и поисковые подсказки в Wordstat, а затем повторите инструкцию.
Также экономит до 8 часов автоматическая кластеризация . Это разбивка всех ключевых фраз на смысловые группы, под которые создается структура сайта, фильтры, категории товаров и так далее.
Для этого загрузите ваш файл со всеми ключевыми фразами в инструмент
кластеризации и в течение 10–30 минут , в зависимости от количества ключевиков, вы получите отчет .Если группировка не удовлетворяет качеством, не выходя из проекта, щелкните по значку “настройки ” и поставьте силу связи сильнее/слабее. Изменение настроек в пределах одного проекта бесплатное, перегруппировка семантики длится не больше 1 минуты.
Если вы уже собираете семантику с помощью сервисов через интерфейс, пришло время познакомить вас с API. Это набор функций, позволяющих пользователям получать доступ к данным или компонентам сервиса, в нашем случае - Serpstat. Преимущество работы по API:

А теперь повторим все действия по сбору семантики со второго этапа с помощью API.
Шаг 1. Скопируйте эту таблицу со скриптом в свой Google Диск.
Шаг 2. Скопируйте свой токен в личном профиле Serpstat и вставьте в соответствующее поле в таблице. Также выберите нужную базу поисковика и заполните параметры отбора ключевых фраз, добавьте список ключевых фраз, по которым вы хотите выгрузить отчеты.

Запустите скрипт, парся по очереди отчеты по подбору фраз, поисковых подсказок и похожих/сленговых фраз (см. скрин):

Программа попросит залогиниться через gmail-аккаунт и запросит доступ на разрешение работы. Подтвердите запуск скрипта, минуя предупреждение о небезопасности.
Шаг 3.
Через 30–60 секунд скрипт завершит работу и соберет ключевые слова в рамках заданных параметров.

Также в этом скрипте можно настроить фильтр по минус-словам и любые другие.
Итого мы сэкономили еще несколько часов работы seo-специалиста на сведении всех отчетов в один и сборе данных по каждому ключевому слову в интерфейсе.
Скрипты для работы по API могут писать ваши seo-специалисты, а можно найти
официальные в открытом доступе .Максимально ускоряют сбор семантического ядра без потери качества такие действия:

Семантическое ядро сайта – это полный набор ключевых слов, соответствующих тематике веб-ресурса, по которым пользователи смогут найти его в поисковой системе.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
К примеру, сказочный персонаж баба Яга будет иметь следующее семантическое ядро: баба Яга, баба Яга сказки, баба Яга русские сказки, баба со ступой сказки, баба со ступой и метлой, злая баба волшебница, баба избушка курьи ножки и т.д.
Перед началом работ по продвижению вам необходимо найти все ключи, по которым его могут искать целевые посетители. На основании семантики составляется структура, распределяются ключи, прописываются метатеги, заголовки документов, описания к изображениям, а также разрабатывается анкор-лист для работы со ссылочной массой.
При составлении семантики необходимо решить главную проблему: определить, какую информацию следует опубликовать, чтобы привлечь потенциального клиента.
Составление списка ключей решает еще одну важную задачу: для каждой поисковой фразы вы определяете релевантную страницу, которая полно сможет ответить на вопрос пользователя.
Данная задача решается двумя путями:
По статистике, 60-80% всех фраз и слов относятся к НЧ. Работать при продвижении с ними дешевле и проще. Поэтому вы должны составить максимально объемное ядро фраз, которое будет постоянно дополняться новыми НЧ. ВЧ и СЧ также не стоит игнорировать, но основной упор делайте на расширение списка низкочастотников.
Необходимо выделить главные термины вашего бизнеса и нужд пользователей. К примеру, клиенты прачечной интересуются стиркой и чисткой.
Затем следует определить хвосты и спецификацию (более 2 слов в запросе), которые пользователи добавляют к главным терминам. Этим вы увеличите охват целевой аудитории и снизите частотность терминов (стирка пледов, стирка курток и т.п.).
Используйте этот метод как дополнительный, чтобы определить правильность выбора того или иного КЗ. В этом вам помогут инструменты BuzzSumo, Searchmetrics, SEMRush, Адвсе.
Рассмотрим некоторые самые популярные сервисы.
Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
Составьте следующие списки: категории товаров или услуг (далее -ТУ), названия ТУ их бренды, коммерческие хвосты («купить», «заказать» и т.п.), синонимы, транслитерацию на латинице (или на русском соответственно), профессиональные жаргонизмы («клавиатура» – «клава» и т.п.), технические характеристики, слова с возможными опечатками и ошибками («оренбуржский» вместо «оренбургский» и т.п.), привязки к местности (город, улицы и т.п.).
При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
Сформируйте список стоп-слов и удалите неподходящие КЗ.
Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
При этом ранжирование ухудшается, сайт может быть наказан за переспам, а если у веб-ресурса неправильная структура, то продвигать его будет очень сложно.
Не важно, каким образом вы будете подбирать семантику. При правильном подходе вы получите правильное СЯ, необходимое для успешного продвижения сайта.
Быстрая навигация по этой странице:
Как и практически все другие вебмастеры, я составляю семантическое ядро с помощью программы KeyCollector — это безусловно лучшая программа для составления семантического ядра. Как ей пользоваться — это тема для отдельной статьи, хотя и в Интернете полно информации на этот счет — рекомендую, к примеру, мануал от Дмитрия Сидаша (sidash.ru).
Поскольку поставлен вопрос о примере составления ядра — привожу пример.
Предположим, у нас сайт посвящен британским кошкам. Вбиваю в «Список фраз» словосочетание «британская кошка» и нажимаю на кнопку «Парсить».
Получаю длинный список фраз, который будет начинаться со следующих фраз (приведена фраза и частнотность):
Британские кошки 75553 британские кошки фото 12421 британская вислоухая кошка 7273 питомник британских кошек 5545 кошки британской породы 4763 британская короткошерстная кошка 3571 окрасы британских кошек 3474 британские кошки цена 2461 кошка голубая британская 2302 британская вислоухая кошка фото 2224 вязка британских кошек 1888 британские кошки характер 1394 куплю британскую кошку 1179 британские кошки купить 1179 длинношерстная британская кошка 1083 беременность британской кошки 974 кошка британская шиншилла 969 кошки британской породы фото 953 питомник британских кошек москва 886 окрас британских кошек фото 882 британские кошки уход 855 британская короткошерстная кошка фото 840 шотландские и британские кошки 763 имена британских кошек 762 кошка британская голубая фото 723 фото британской голубой кошки 723 британская кошка черная 699 чем кормить британских кошек 678
Сам список намного больше, я только привел его начало.
Исходя из этого списка, у меня на сайте будут статьи про разновидности кошек (вислоухая, голубая, короткошерстная, длинношерстная), будет статья про беременность этих животных, про то, чем их кормить, про имена и так далее по списку.
Под каждую статью берется один основной такой запрос (=тема статьи). Впрочем, только одним запросом статья не исчерпывается — в нее также добавляются другие подходящие по смыслу запросы, а также разные вариации и словоформы основного запроса, которые можно найти в Кей Коллекторе ниже по списку.
Например, со словом «вислоухая» имеются следующие ключи:
Британская вислоухая кошка 7273 британская вислоухая кошка фото 2224 британская вислоухая кошка цена 513 порода кошек британская вислоухая 418 британская голубая вислоухая кошка 224 шотландские вислоухие и британские кошки 190 кошки британской породы вислоухие фото 169 британская вислоухая кошка фото цена 160 британская вислоухая кошка купить 156 британская вислоухая голубая кошка фото 129 британские вислоухие кошки характер 112 британская вислоухая кошка уход 112 вязка британских вислоухих кошек 98 британская короткошерстная вислоухая кошка 83 окрас британских вислоухих кошек 79
Чтобы не было переспама (а переспам может быть и по совокупности использования слишком большого количества ключей в тексте, в заголовке, в и т.д.), я бы не стал брать их все с включением основного запроса, но отдельные слова из них имеет смысл употребить в статье (фото, купить, характер, уход и т.д.) для того, чтобы статья лучше ранжировалась по большому количеству низко-частотных запросов.
Таким образом, у нас под статью про вислоухих кошек сформируется группа ключевых слов, которые мы употребим в статье. Точно также сформируются и группы ключевиков под другие статьи — вот и ответ на вопрос о том, как создать семантическое ядро сайта.
Еще есть немаловажный момент, связанный с точной частотностью и конкуренцией — их обязательно нужно собрать в Key Collector. Для этого нужно выделить все запросы галочками и на вкладке «Частотности Yandex.Wordstat» нажать кнопку «Собрать частотности «!» — будет показана точная частнотность каждой фразы (т.е. именно с таким порядком слов и в таком падеже), это намного более точный показатель, чем общая частотность.
Для проверки конкуренции в том же Key Collector нужно нажать кнопку «Получить данные для ПС Яндекс» (или для Google), далее нажать «Рассчитать KEI по имеющимся данным». В результате программа соберет, сколько главных страниц по данному запросу находится в ТОП-10 (чем больше — тем сложнее туда пробиться) и сколько страниц в ТОП-10 содержат такой title (аналогично, чем больше — тем сложнее пробиться в топ).
Дальше нужно действовать исходя из того, какая у нас стратегия. Если мы хотим создать всеобъемлющий сайт про кошек, то нам не так важна точная частотность и конкуренция. Если же нам нужно только опубликовать несколько статей — то берем запросы, у которых самая высокая частотность и при этом самая низкая конкуренция, и на их основании пишем статьи.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
О наиболее важных этапах сбора и пойдет речь ниже!
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :

Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
| курсы поисковой оптимизации |
| продам раскрученный сайт |
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:
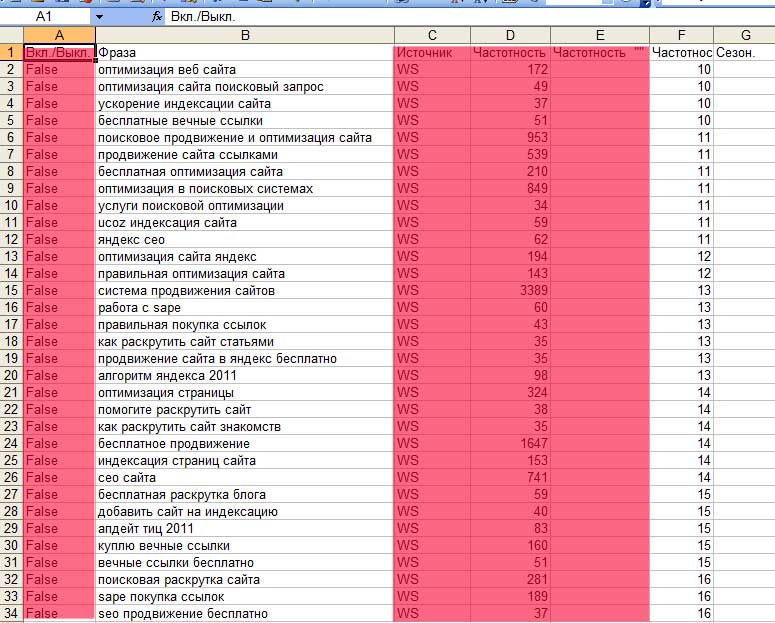
Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:


Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
Органический поиск - самый эффективный источник привлечения целевого трафика. Чтобы его использовать, необходимо сделать сайт интересным и видимым для пользователей поисковых систем Яндекс и Google. Здесь не нужно изобретать велосипед: достаточно определить, чем интересуется аудитория вашего проекта и как она ищет информацию. Эта задача решается при построении семантического ядра.
Семантическое ядро - набор слов и словосочетаний, отражающих тематику и структуру сайта. Семантика - раздел языковедения, изучающий смысловую наполненность единиц языка. Поэтому термины «семантическое ядро» и «смысловое ядро» тождественны. Запомните эту реплику, она не даст вам скатиться до keyword stuffing или напичкивания контента ключевыми словами.
Составляя смысловое ядро, вы отвечаете на глобальный вопрос: какую информацию можно найти на сайте. Поскольку одним из главных принципов бизнеса и маркетинга считается клиентоориентированность, на создание семантического ядра можно смотреть с другой стороны. Вам нужно определить, с помощью каких поисковых запросов пользователи ищут информацию, которая будет опубликована на сайте.
Построение смыслового ядра решает еще одну задачу. Речь идет о распределении поисковых фраз по страницам ресурса. Работая с ядром, вы определяете, какая страница точнее всего отвечает на конкретный поисковый запрос или группу запросов.
Оба подхода так или иначе работают. Но логичнее сначала планировать структуру сайта, а потом определять запросы, по которым пользователи смогут найти ту или иную страницу. В этом случае вы остаетесь проактивным: сами выбираете, что хотите рассказывать потенциальным клиентам. Если вы подгоняете структуру ресурса под ключи, то остаетесь объектом и реагируете на среду, а не активно ее меняете.
Здесь нужно четко подчеркнуть разницу между «сеошным» и маркетинговым подходом к построению ядра. Вот логика типичного оптимизатора старой школы: чтобы создать сайт, нужно найти ключевые слова и выбрать фразы, по которым просто попасть в топ выдачи. После этого необходимо создать структуру сайта и распределить ключи по страницам. Контент страницы нужно оптимизировать под ключевые фразы.
Вот логика бизнесмена или маркетолога: нужно решить, какую информацию транслировать аудитории с помощью сайта. Для этого необходимо хорошо знать свою отрасль и бизнес. Сначала нужно запланировать приблизительную структуру сайта и предварительный список страниц. После этого при построении семантического ядра надо узнать, как аудитория ищет информацию. С помощью контента необходимо отвечать на вопросы, которые задает аудитория.
К каким негативным последствиям приводит использование «сеошного» подхода на практике? Из-за развития по принципу «плясать от печки» падает информационная ценность ресурса. Бизнес должен формировать тренды и выбирать, что говорить клиентам. Бизнес не должен ограничиваться реакциями на статистику поисковых фраз и создавать страницы только ради оптимизации сайта под какой-то ключ.
Планируемый результат построения семантического ядра - это список ключевых запросов, распределенных по страницам сайта. Он содержит URL страниц, поисковые запросы и указание их частотности.
Структура сайта представляет собой иерархическую схему страниц. С ее помощью вы решаете несколько задач: планируете информационную политику и логику подачи информации, обеспечиваете юзабилити ресурса, обеспечиваете соответствие сайта требованиям поисковых систем.
Чтобы построить структуру, воспользуйтесь удобным вам инструментом: редакторами таблиц, Word или другим ПО. Также вы можете нарисовать структуру на листе бумаги.
При планировании иерархии отвечайте на два вопроса:
Представьте, что планируете структуру сайта небольшой кондитерской. Ресурс включает информационные страницы, раздел публикаций и витрину или каталог продуктов. Визуально структура может выглядеть так:

Для дальнейшей работы с семантическим ядром оформите структуру сайта в виде таблицы. В ней укажите названия страниц и обозначьте их подчиненность. Также включите в таблицу колонки для указаний URL страниц, ключевых слов и их частотности. Таблица может выглядеть так:

Колонки URL, «Ключи» и «Частотность» вы заполните позже. Сейчас переходите к поиску ключевых слов.
Чтобы подобрать семантическое ядро, вы должны понимать, что такое ключевые слова и какие ключи использует аудитория . С этими знаниями вы сможете корректно использовать один из инструментов для подбора ключевых слов.
Ключи - это слова или фразы, которые используют потенциальные клиенты, чтобы найти необходимую информацию. Например, чтобы приготовить торт, пользователь вводит в поисковую строку запрос «наполеон рецепт с фото».
Ключевые слова классифицируются по нескольким признакам. По популярности выделяют высоко-, средне- и низкочастотные запросы. По разным данным, поисковые фразы объединяются в группы так:
Разница в оценке частотности связана с разной популярностью тематик. Если вы создаете ядро для интернет-магазина, торгующего ноутбуками, фраза «купить ноутбук samsung» с частотой показа около 6 тыс. в месяц будет среднечастотной. Если вы создаете ядро для сайта спортивного клуба, запрос «секция айкидо» с частотой показов около 1000 запросов будет высокочастотным.
Что нужно знать о частотности при составлении семантического ядра? По разным данным, от двух третьих до четырех пятых всех запросов пользователей относятся к низкочастотным. Поэтому вам нужно строить максимально широкое семантическое ядро. На практике оно должно постоянно расширяться за счет низкочастотных фраз.
Значит ли это, что высоко- и среднечастотные запросы можно игнорировать? Нет, вы не обойдетесь без них. Но в качестве основного ресурса привлечения целевых посетителей рассматривайте низкочастотные ключи.
По потребностям пользователей ключи объединяются в такие группы:
Некоторые специалисты выделяют в отдельную группу навигационные запросы. С их помощью аудитория ищет информацию на конкретных сайтах. Вот несколько примеров: «ноутбуки связной», «сити экспресс отследить доставку», «зарегистрироваться в LinkedIn». Неспецифичные вашему бизнесу навигационные запросы при составлении семантического ядра можно игнорировать.
Как использовать этот способ классификации при построении семантического ядра? Во-первых, вы должны учитывать нужды аудитории при распределении ключей по страницам и создании контент-плана. Здесь все очевидно: публикации информационных разделов должны отвечать на информационные запросы. Здесь же должна быть большая часть ключевых фраз без выраженного намерения. На транзакционные вопросы должны отвечать страницы из разделов «Магазин» или «Витрина».
Во-вторых, следует помнить, что многие транзакционные вопросы относятся к коммерческим. Чтобы привлекать естественный трафик по запросу «купить смартфон Samsung», вам придется конкурировать с «Евросетью», «Эльдорадо» и другими бизнес-тяжеловесами. Избежать неравной конкуренции можно с помощью рекомендации, приведенной выше. Максимально расширяйте ядро и снижайте частотность запросов. Например, частотность запроса «купить смартфон Samsung Galaxy s6» на порядок ниже частотности ключа «Купить смартфон Samsung Galaxy».
Поисковые фразы состоят из нескольких частей: тела , спецификатора и хвоста . Это можно рассмотреть на примере.
Что можно сказать о запросе «торт»? По нему нельзя определить намерение пользователя. Он высокочастотный, что определяет высокую конкуренцию в выдаче. Использование этого запроса для продвижения принесет большую долю нецелевого трафика, что негативно сказывается на поведенческих метриках. Высокочастотность и неспецифичность запроса «торт» определяется его анатомией: он состоит только из тела.
Обратите внимание на запрос «купить торт». Он состоит из тела «торт» и спецификатора «купить». Последний определяет намерение пользователя. Именно спецификаторы указывают на принадлежность ключа к транзакционным или информационным. Посмотрите на примеры:
Иногда спецификаторы могут выражать прямо противоположные намерения пользователя. Простой пример: пользователи планируют купить или продать машину.
Теперь посмотрите на запрос «купить торт с доставкой». Он состоит из тела, спецификатора и хвоста. Последний не меняет, а детализирует намерение или информационную потребность пользователя. Посмотрите на примеры:

В каждом случае видно намерение человека приобрести торт. А хвост ключевой фразы детализирует эту потребность.
Знание анатомии поисковых фраз позволяет вывести условную формулу подбора ключей для семантического ядра. Вы должны определить базовые термины, связанные с вашим бизнесом, продуктом и нуждами пользователей. Например, клиенты кондитерской фирмы интересуются тортами, выпечкой, печеньем, пирожными, капкейками и другими кондитерскими изделиями.
После этого вам нужно найти хвосты и спецификаторы, которые аудитория проекта использует с базовыми терминами. Благодаря «хвостатым» фразам вы одновременно увеличиваете охват и уменьшаете конкурентность ядра.
Длинный хвост или long tail - это термин, определяющий стратегию продвижения ресурса по низкочастотным ключевым запросам. Она заключается в использовании максимального числа ключей с низким уровнем конкуренции. Продвижение по низкочастотникам обеспечивает высокую эффективность маркетинговых кампаний. Это объясняется следующими факторами:
Для больших сайтов семантическое ядро может содержать десятки тысяч запросов, и подобрать и грамотно сгруппировать их руками практически невозможно.
Есть достаточно много инструментов для подбора ключевых слов. Вы можете построить ядро с помощью платных или бесплатных сервисов и программ. Выбирайте конкретное средство в зависимости от стоящих перед вами задач.
Вы не обойдетесь без этого инструмента, если занимаетесь интернет-маркетингом профессионально, развиваете несколько сайтов или составляете ядро для большого сайта. Вот список основных задач, которые решает программа:

Key Collector - многофункциональный инструмент, который автоматизирует операции, необходимые для построения семантического ядра. Программа платная. Вы можете выполнить все действия, которые «умеет» Key Collector, с помощью альтернативных бесплатных инструментов. Но для этого вам придется использовать несколько сервисов и программ.
Это бесплатный инструмент от создателей Key Collector. Программа собирает ключевые слова через Wordstat, определяет частотность запросов, парсит поисковые подсказки.
Чтобы воспользоваться программой, в настройках укажите логин и пароль от аккаунта «Директ». Не используйте основной аккаунт, так как «Яндекс» может заблокировать его за автоматические запросы.

Создайте новый проект. На вкладке «Данные» выберите опцию «Добавить фразы». Укажите поисковые фразы, которые предположительно использует аудитория проекта для поиска информации о продуктах.

В разделе меню «Сбор ключевых слов и статистики» выберите нужную опцию и запустите программу. Например, определите частотность ключевых фраз.

Инструмент позволяет подобрать ключевые слова, а также автоматически выполнить некоторые задачи, связанные с анализом и группировкой запросов.
Чтобы увидеть, по каким фразам страницы показывается в выдаче Яндекса, в панели Яндекс.Вебмастера нужно открыть вкладку «Поисковые запросы» -> «Последние запросы».

Мы видим фразы, по которым были переходы или сниппет сайта показывался в ТОП–50 Яндекса за последние 7 дней.
Чтобы посмотреть данные только по странице, которая нас интересует, нужно использовать фильтры.

На этом возможности поиска дополнительных фраз в Яндекс.Вебмастере не ограничиваются.
Переходим на вкладку «Поисковые запросы» -> «Рекомендованные запросы».

Здесь может быть не так много фраз, но можно найти дополнительные фразы, по которым продвигаемая страница не попадает в ТОП–50.
Большим минусом анализа видимости в Яндекс.Вебмастере, конечно же, является то, что данные есть только за последние 7 дней. Чтобы немного обойти это ограничение, можно попробовать дополнить список, используя вкладку «Поисковые запросы» -> «История запросов».
Здесь вам нужно будет выбрать «Популярные запросы».

Вы получите список наиболее популярных фраз за последние 3 месяца.
Чтобы получить фразы из Google Search Console, переходим на вкладку «Поисковый трафик» -> «Анализ поисковых запросов». Далее выбираем «Показы», «CTR», «Клики». Это позволит видеть больше информации, которая может быть полезна при анализе фраз.

По умолчанию на вкладке отображаются данные за 28 дней, но есть возможность расширить диапазон до 90 дней. Также можно выбрать нужную страну.

В итоге получаем список запросов, аналогичный показанному на скриншоте.
Google уже сделал доступными некоторые инструменты новой версии панели. Чтобы посмотреть запросы для страницы, переходим на вкладку «Статус» - > «Эффективность».
В новой версии фильтры расположены иначе, но логика фильтрации сохраняется. Думаю, нет смысла останавливаться на этом вопросе. Из значимых отличий стоит отметить возможность анализа данных за более длительный период, а не только за 90 дней. Существенное преимущество, если сравнивать с Яндекс.Вебмастером (только 7 дней).

Сайты конкурентов - отличный источник идей ключевых слов. Если вас интересует конкретная страница, определить поисковые фразы, под которые она оптимизирована, можно вручную. Чтобы найти основные ключи, обычно достаточно прочитать материал или проверить содержимое мета-тега keywords в коде страницы. Также вы можете воспользоваться сервисами семантического анализа текстов, например, Istio или Advego .

Если вам необходимо проанализировать сайт целиком, воспользуйтесь сервисами комплексного конкурентного анализа:

Вы можете использовать и другие инструменты для сбора ключевых фраз. Вот несколько примеров: Google Trends , WordTracker , WordStream , Ubersuggest , Топвизор . Но не спешите освоить все сервисы и программы сразу. Если вы составляете семантическое ядро для собственного небольшого сайта, воспользуйтесь бесплатным инструментом, например, сервисом подбора ключевых слов «Яндекс» или планировщиком Google.
Процесс подбора ключевых фраз объединяется в несколько этапов:
Внесите в таблицу или запишите на бумаге общие поисковые фразы, связанные с вашим бизнесом и продуктами. Соберите коллег и проведите мозговой штурм. Фиксируйте все предложенные идеи без обсуждений.
Ваш список будет выглядеть примерно так:

Большинство ключей, которые вы записали, характеризуются высокой частотностью и низкой специфичностью. Чтобы получить средне- и низкочастотные поисковые фразы с высокой специфичностью, вам нужно максимально расширить ядро.
Эту задачу вы будете решать с помощью инструментов для подбора ключевых слов, например, Wordstat. Если ваш бизнес имеет региональную привязку, в настройках выберите соответствующий регион.
С помощью сервиса подбора ключевых фраз вам необходимо проанализировать все записанные на предыдущем этапе ключи.

Скопируйте фразы из левой колонки Wordstat и вставьте в таблицу. Обратите внимание на правую колонку Wordstat. В ней «Яндекс» предлагает фразы, которые люди использовали вместе с основным запросом. В зависимости от содержания вы можете сразу выбрать подходящие ключи из правой колонки или скопировать список целиком. Во втором случае неподходящие запросы будут отсеяны на следующем этапе.
А результатом этого этапа работы будет список поисковых фраз для каждого базового ключа, который вы получили с помощью мозгового штурма. В списках могут быть сотни или тысячи запросов.

Это самый трудозатратный этап работы с ядром. Вам необходимо вручную удалить из ядра неподходящие по смыслу поисковые фразы.
Не используйте в качестве критерия оценки ключей частотность, конкурентность или другие чисто «сеошные» метрики. Знаете, почему оптимизаторы старой школы считают мусорными те или иные поисковые фразы? Например, возьмите ключ «диетический торт». Сервис Wordstat прогнозирует для него 3 показа в месяц в регионе Череповец.

Чтобы продвигать страницы по конкретным ключам, олдскульные сеошники покупали или арендовали ссылки. Кстати, некоторые специалисты используют этот подход до сих пор. Понятно, что поисковые фразы с низкой частотностью в большинстве случаев не окупают средства, потраченные на покупку ссылок.
Теперь посмотрите на фразу «диетические торты» глазами обычного маркетолога. Некоторые представители ЦА кондитерской фирмы действительно интересуются такими продуктами. Поэтому ключ можно и нужно включить в семантическое ядро. Если кондитерская готовит соответствующие продукты, фраза пригодится в разделе описаний товаров. Если фирма по каким-то причинам не работает с диетическими тортами, ключ можно использовать в качестве контент-идеи для информационного раздела.
Какие фразы можно смело исключать из списка? Вот примеры:
После удаления неподходящих фраз вы получили список запросов для базового ключа «торты на заказ». Такие же списки необходимо составить для других базовых ключей, полученных на этапе мозгового штурма. После этого переходите к группировке ключевых фраз.
Поисковые фразы, с помощью которых пользователи находят или будут находить ваш сайт, объединяются в семантические кластеры, этот процесс называют кластеризацией поисковых запросов . Это близкие по смыслу группы запросов. Например, в семантический кластер «Торт» входят все ключевые фразы, связанные с этим словом: рецепты тортов, заказать торт, фото тортов, свадебный торт и т.д.
Семантический кластер - это группа объединенных по смыслу запросов. Он представляет собой многоуровневую структуру. Внутри кластера первого порядка «Торт» есть кластеры второго порядка «Рецепты тортов», «Заказ тортов», «Фотографии тортов». Внутри кластера второго порядка «Рецепты тортов» теоретически можно выделить третий порядок кластеризации: «Рецепты тортов с мастикой», «Рецепты бисквитных тортов», «Рецепты песочных тортов». Число уровней в кластере зависит от обширности тематики. На практике в большинстве тематик достаточно внутри кластеров первого порядка выделить специфичные бизнесу кластеры второго порядка.

Теоретически семантический кластер может иметь много уровней.
На практике работать придется с кластерами первого и второго уровней
Большую часть кластеров первого уровня вы определили во время мозгового штурма, когда записывали базовые ключевые фразы. Для этого достаточно разбираться в собственном бизнесе, а также подглядывать в схему сайта, которую вы составили до начала работы над семантическим ядром.
Очень важно корректно выполнить кластеризацию на втором уровне. Здесь поисковые фразы меняются с помощью спецификаторов, обозначающих намерения пользователей. Простой пример - кластеры «рецепты тортов» и «торты на заказ». Поисковые фразы первого используют люди, нуждающиеся в информации. Ключи второго кластера используют клиенты, желающие купить торт.
Поисковые фразы для кластера «торты на заказ» вы определили с помощью Wordstat и ручного отсева. Их необходимо распределить между страницами раздела «Торты».

Например, в кластере есть поисковые запросы «футбольные торты на заказ» и «торты на заказ футбольная тематика».

Если в ассортименте фирмы есть соответствующий продукт, в разделе «Торты из мастики» необходимо создать соответствующую страницу. Внесите ее в структуру сайта: укажите название, URL и поисковые фразы с частотностью.

С помощью сервиса «Подбор ключевых слов» или аналогичных инструментов посмотрите, какие еще поисковые фразы используют потенциальные клиенты, чтобы найти торты с футбольным оформлением. Внесите подходящие в список ключевых слов страницы.

В списке поисковых фраз кластера удобным вам способом отметьте распределенные ключи. Распределите оставшиеся поисковые фразы.
Если необходимо, меняйте структуру сайта: создавайте новые разделы и категории. Например, страница «торты на заказ щенячий патруль» должна войти в раздел «Детские торты». Одновременно она может входить в раздел «Торты из мастики».

Обратите внимание на два момента. Во-первых, в кластере может не оказаться подходящих фраз для страницы, которую вы планируете создать. Это может произойти по разным причинам. Например, к ним относятся несовершенство инструментов сбора поисковых фраз или их некорректное использование, а также низкая популярность продукта.
Отсутствие в кластере подходящего ключа - не повод отказаться от создания страницы и продажи продукта. Например, представьте, что кондитерская фирма продает детские торты с изображением героев мультфильма «Свинка Пеппа». Если в список не попали соответствующие ключи, уточните потребности аудитории с помощью Wordstat или другого сервиса. В большинстве случаев подходящие запросы найдутся.

Во-вторых, даже после удаления лишних ключей в кластере могут остаться поисковые фразы, которые не подходят для созданных и запланированных страниц. Их можно игнорировать или использовать в другом кластере. Например, если кондитерская по каким-то причинам принципиально не продает торт «Наполеон», соответствующие ключевые фразы можно использовать в разделе «Рецепты».

Группировку поисковых запросов можно проводить в ручную, в программах Excel или Google таблицы, или автоматизировано, при помощи специальных приложений и сервисов.
Кластеризация позволяет понять, каким образом запросы могут быть распределены по страницам сайта для их наиболее быстрого и эффективного продвижения.
Автоматическая кластеризация или группировка поисковых запросов семантического ядра проводится на основе анализа сайтов входящих в ТОП-10 выдачи поисковых систем Google и Yandex.
Как работает автоматическая группировка запросов : для каждого из запросов просматривается выдача среди ТОП-10 сайтов. Если хотя бы среди 4-6 из них есть совпадения, то запросы можно сгруппировать для размещения на одной странице.
Автоматическая группировка наиболее быстрый и эффективный способ объединения ключевых слов для формирования практически готовой к применению структуре сайта.
Если не верно, с точки зрения статистики поисковых систем, сформировать структуру сайта и распределить запросы по его страницам, успешно продвинуть страницы в ТОП будет, увы, невозможно!
Среди сервисов автоматизирующих группировку ключевых слов стоит выделить:
После распределения всех ключей вы получите список существующих и запланированных страниц сайта с указанием URL, поисковых фраз и частотности. Что с ними делать дальше?
Таблица с семантическим ядром должна стать дорожной картой и основным источником идей при формировании:
Посмотрите: у вас есть список с предварительным названием страниц и поисковыми фразами. Они определяют потребности аудитории. При составлении контент-плана вам остается уточнить название страницы или публикации. Включите в него основной поисковый запрос. Это не всегда самый популярный ключ. Кроме популярности, запрос в названии должен лучше всего отражать потребность аудитории страницы.
Остальные поисковые фразы используйте в качестве ответа на вопрос «о чем писать». Помните, вам не нужно во что бы то ни стало вписать все поисковые фразы в информационный материал или в описание продукта. Контент должен раскрывать тему и отвечать на вопросы пользователей. Еще раз обратите внимание: нужно фокусироваться на информационных потребностях, а не на поисковых фразах и их вписывании в текст.
Специфика подготовки и кластеризации семантики , заключается в наличии четырех очень важных, для последующего , групп страниц:
Выше мы уже рассказывали про разные типы поисковых запросов: информационные, транзакционные, коммерческие, навигационные. Для страниц разделов и товаров интернет-магазина, в первую очередь, интересны транзакционные, т.е. запросы, используя которые пользователи поисковых систем хотят увидеть сайты, где они смогут совершить покупку.
Начинать формирование ядра необходимо со списка товаров, которые вы уже продаете или планируете продавать.
Для интернет-магазинов:

Устанавливая каждое приложение, владелец смартфона соглашается с запросами на доступ к определенным данным и возможностям...
С тем, что количество паролей, которые надо запомнить, точно больше, чем места для них в голове, столкнулись, наверное,...

Для успешной работы с любым оборудованием требуется наличие драйверов и своевременное их обновление. В случае с...
Я установил обновление для авторов (версия 1703) на свой компьютер с Windows 10 Pro, но теперь я получаю обновления для...

GIF – растровый формат графических изображений, поддерживающий не более 256 цветов и применяющийся в первую очередь для...
Если вам еще не приходилось пользоваться фирменным облачным хранилищем от компании Apple, вы многое потеряли. Помимо...

Компания Apple предоставляет своим пользователям широкий выбор сервисов, помогающих найти, сохранить и...

Решение задачи, связанной с тем, как настроить принтер на печать с компьютера является не такой уж сложной, как...
Практически все Android-устройства умеют подключаться к мобильному интернету, используя ресурсы сотовых...

Статьи и ЛайфхакиЕсли вы планируете использовать телефон не только для звонков, но и для выхода в Глобальную...
Skype Portable - это портативная (Portable) версия всемирно известного бесплатного мессенжера. Бесплатная...
При входе посетителей на сайт, в систему банковских платежей, требуется авторизоваться. Что такое авторизация?...
Подробности Категория: Компьютеры, ПО Опубликовано 16.03.2013 12:03 После установки Windows на ноутбук, по...
MSN вирус — это опасный троян, распространяемый с помощью MSN Messenger. По существу, можно сказать, что этому...
С тем, что количество паролей, которые надо запомнить, точно больше, чем места для них в голове, столкнулись,...
Для успешной работы с любым оборудованием требуется наличие драйверов и своевременное их обновление. В случае с...